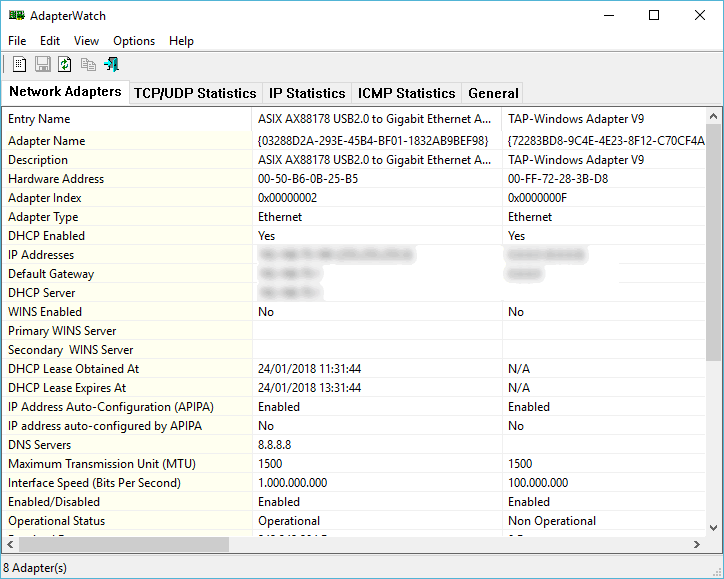
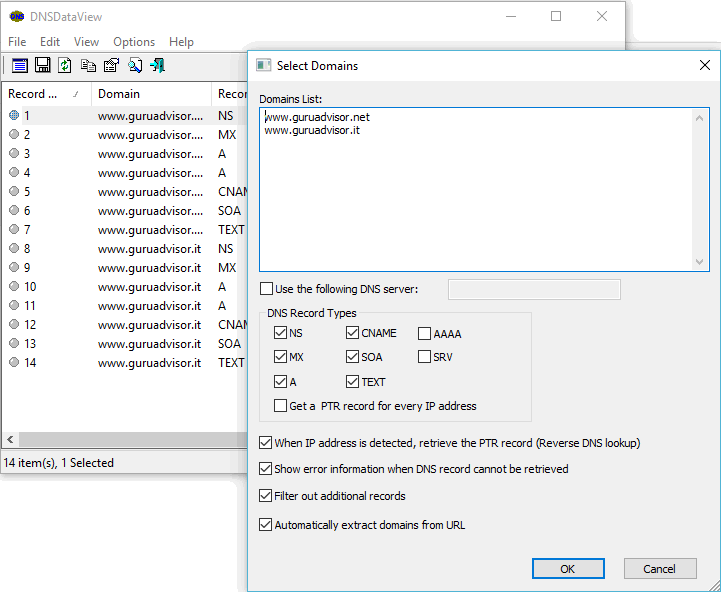
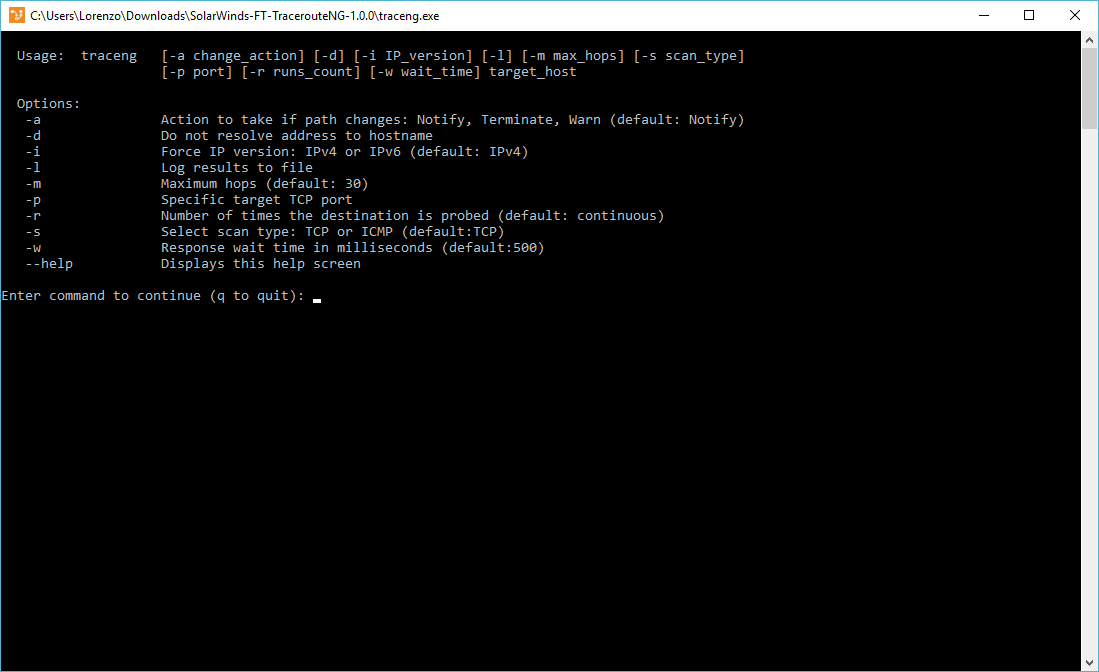
Software development doesn’t include the knowledge of programming languages, debug techniques and how to optimize the code only, it also deals with a proper and coherent management of the different versions of the same code: versioning.
Be it the work of a single developer or of a team distributed on different geographic areas, versioning is an essential aspect of software development, due to large codebases to manage as well. In order to face the challenge, several platform were designed, with Git standing on top: Git is a versioning engine that can be managed via CLI or graphical interface, locally or via Web.
Git is also at the basis of many products/services, with GitHub and BitBucket being the most used.
![]()
In this article we are going to get acquainted with Git by leveraging Gitlab as a testing environment to discover its fundamental aspects: what is Git and how it works, what commits, repositories and branches are, and the main differences between on-premises and Cloud versions.
What is a Version Control System
Generally speaking, a VCS, or Version Control System, is a software that helps to manage versions, modifications and releases of software and general code. The main goal is to track in a complete and chronological way all the work done through time so to act coherently in case of roll backs, integrations, mistakes, etc.. . Additional features of a VCS include the addition comments, and the creation branches, or deviations from the main “story line”, which also help to maintain an adequate documentation.
To quickly sum up, we can say that a version control system tracks the modifications and who made them, allows the roll back in any previous state and enables a collective development.
Git distinguishes from the other softwares as is considers its data as a series of snapshots for the same micro file system: it doesn’t work in terms of cloning and later integration into the origin file, it just tracks in an pseudo-incremental way each file in the repository.
What is Git and how it works
Conceived from the mighty mind of Linus Torvalds while developing the Linux kernel (actually, to help its development), Git is a VCS that allows users (clients) to act as a server themselves. Engine of choice of the Gitlab platform, it also has a local copy of repositories.
Git is open source, quick and secure that offers a great support to non-linear development; it’s available on Windows, macOS and Linux. Git works as a command line tools, but there are graphical interface wrappers that can make it easier and more convenient to use for some users: an interface can also be implemented as as Web service, expanding its opportunities.
Git leverages four basic concepts: snapshots, commits, repositories and branches.
Snapshot
s
Snapshots are Git’s way to track the code in a chronological way. A snapshot essentially records the actual state of files at a given time. The user decides when to create a snapshot and which files to include; later, a snapshot can be used to rollback or identify modifications and bugs.
Commits
A commit is the action that generates snapshots: therefore commits represents the way how modifications to the code -thus the work done- is saved. Specifically, a commit includes the saving of one or more files inside the repository.
Repositories
A repository is an ordered collection of files that includes a chronology and commits metadata. It can reside on the local computer or on a remote server, like GitLab or a Web platform like GitHub or BitBucket.
There are four main actions that an user can apply to a repository.
- Init: it initializes a new repository inside the working directory.
- Clone: it clones an existing Git repository from a remote server.
- Pull: it downloads data from a remote repository.
- Push: it uploads branches and data to a remote repository.
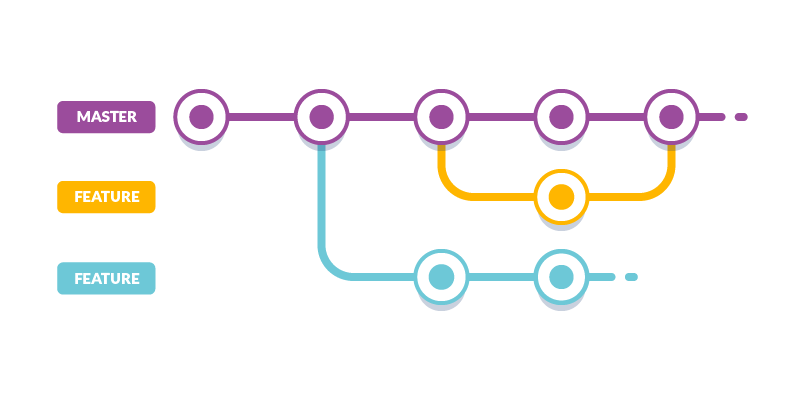
Branch
es
A branch is a deviation from the underlying main tree structure of the repository, as shown in the previous picture.
Git archives files and keeps a tree of them, which makes it clear and intuitive to see the differences of a single file or whole project after it has been modified from the first commit.
Note that each commit must reside on some branch; a repository can host multiple branches: the primary branch is called master.
Gitlab: from theory to practice
Gitlab is an on-line platform based on Git which makes collaborative development easier; in order to avoid confusion between Gitlab and GitHub, please remember that the latter was born to host projects (Git-based, naturally) for free if open source, upon a fee if private. The former is a free product available in self-hosted mode or SaaS.
A self-hosted solution installs Gitlab on your own server or into a private Cloud, in any case you maintain control on the platform and the data it hosts: it’s the typical scenario for a company that needs to access exclusively and at any given time to its own projects; if implemented properly, a self-hosted version can assure more safety from external attacks and an improved access speed due to the exclusivity of the usage. This version is free.
The SaaS offering (Software as a Service, gitlab.com) is in a Cloud environment, albeit with some differences from the aforementioned GitHub and BitBucket. For instance it offers an unlimited number of private repositories with unlimited number of collaborators for the single project, and Continuous Integration and Continuous Delivery and Container Registry (to manage Docker images) services for DevOps contexts.
gitlab.com also offers Mastermost, and open source team chat solution akin to Slack.
In the IT world, DevOps (portmanteau between the terms Development and Operations, ie deployment and release) is a software development paradigma that leverages on communication, integration and collaboration among developers and operators ofIT.
DevOps is the reaction to the interdependence between software development and IT operations and aims to a quicker and more efficient development.
In the next issue we will take hands-on lab with Git and GitLab with a dedicated tutorial-article.

")