La stesura di software, firmware e codice in generale, non coinvolge solo la conoscenza dei linguaggi di programmazione, le capacità di debug e di ottimizzazione del codice, ma anche anche la corretta e coerente gestione delle versioni del codice stesso (versioning).
Che si tratti del lavoro di un singolo sviluppatore, o di un team magari anche distribuito dal punto di vista geografico, il versioning è diventato un aspetto fondamentale per lo sviluppo, anche in virtù di software sempre più vasti e con decine di migliaia di righe di codice da gestire. In questo contesto sono nate alcune piattaforme specializzate, tra cui spitta Git: un motore di versioning gestibile da interfaccia grafica, sia localmente sia via Web. Sulla base di Git si sono poi sviluppati diversi prodotti, come Gitlab e Bitbuket per citare le due più famose.
![]()
In questo articolo andremo a conoscere gradualmente Git – sfruttando Gitlab come ambiente di test - in tutti i suoi aspetti fondamentali e operativi: che cos’è GIT e come funziona, cosa sono i commit, i repository e i branch e le differenze tra la versione Cloud e on-premises.
Cosa si intende per sistema di controllo di versione
In linea generale si può definire sistema di controllo di versione (o versioning oppure VCS, acronimo di Version Control Systems) tutto ciò che permette di gestire le versioni, modifiche, release di software e codice in generale. Lo scopo principale è quello di tracciare in modo completo e in ordine cronologico le modifiche effettuate nel tempo, per poter agire in modo coerente in caso di rollback, integrazioni, rilevazioni di errori etc. La possibilità di aggiungere commenti e aprire sotto-rami di sviluppo sono altre funzioni disponibili e fondamentali per accompagnare ogni modifica con una documentazione adeguata.
Riassumendo in modo sintetico, possiamo dire che un sistema di controllo versioni si occupa di tenere traccia delle modifiche apportate nel tempo e dei relativi autori, di effettuare il rollback in qualsiasi punto e di consentire lo sviluppo collaborativo in modo coerente.Git si distingue da altri software in commercio, in quanto considera i propri dati come una serie di instantanee di un mini file-system. Quindi non lavora basandosi sulla clonazione e successiva integrazione del file di origine, ma traccia in modo incrementale tutti i file del repository.
Cos'è e come funziona Git
Nato dalla mente di Linus Torvalds durante lo sviluppo del kernel Linux, Git è un software di controllo di versione che permette ad ogni utente (client) di fare anche da server per sé stesso. Inoltre possiede una copia locale del repository ed è il motore della piattaforma GitLab.
Git è un sistema di controllo delle versioni distribuito ed utilizzabile gratuitamente (open source), veloce, sicuro e costituisce un ottimo supporto allo sviluppo non-lineare ed è inoltre disponibile per Windows, MacOs e, naturalmente, Linux. Di base Git funziona tramite linea di comando, perciò per renderne l’utilizzo più agevole è conveniente ricorrere a un’interfaccia grafica che semplifichi l’utilizzo: l'interfaccia può anche essere implementata in un servizio web accessibile via Internet, che ne espande ulteriormente le potenzialità. I tre concetti base di Git sono: snapshot, commit, repository e branch
Snapshot
Gli snapshot (istantanee) sono il modo in cui Git mantiene traccia della cronologia del codice. Uno snapshot essenzialmente registra lo stato attuale di tutti i file in un dato momento. Con Git l’utente può decidere quando e su quali file creare uno snapshot, in modo da poter effettuare il rollback o identificare modifiche e bug.
Commit
Il commit è l’azione con la quale si genera uno snapshot: i commit rappresentano il modo in cui si “salvano” le modifiche fatte al codice. Nello specifico il commit corrisponde al salvataggio di uno o più file aggiornati, sul repository.
Repository
Letteralmente tradotto in deposito o magazzino (ma anche contenitore, se vogliamo) il repository è una collezione di tutti i file, compresi di cronologia e storico dei commit. La parola repository indica un archivio ordinato dove sono raccolti i file del progetto. Il repository può risiedere su un computer locale o su un server remoto come, è nel caso di GitLab o di tutte quelle piattaforme Web che si basano su Git per offrire servizi di versioning: esistono quattro azioni chiave che l’utente può applicare al repository:
- Init: inizializza un nuovo repository all’interno della cartella corrente
- Clone: clona un repository Git esistente dal server remoto
- Pull: scarica dati da un repository remoto
- Push: invia branch e dati a un repository remoto
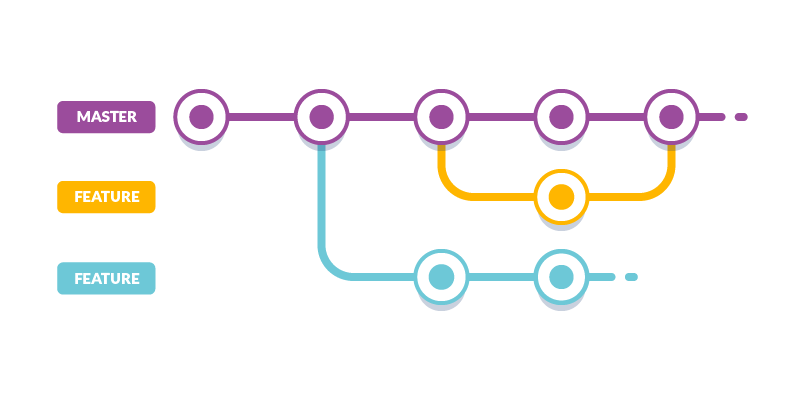
Branch
Letteralmente tradotto in “ramo”, il branch è una branca o diramazione nella struttura ad albero del repository, come mostrato nella figura sottostante. Git archivia i file e li tiene ordinati ad albero, evidenziando come sia facile ed intuitivo poter vedere le differenze di un file (o progetto) dopo che è stato modificato dal primo salvataggio “commit”. È bene ricordare che tutti i commit devono risiedere su qualche branch, possono esserci branch multipli in un singolo repository e per impostazione predefinita il branch primario si chiama master.
GitLab: dalla teoria alla pratica
Si tratta di una piattaforma on-line basata su Git, che facilita lo sviluppo collaborativo di firmware e Per evitare confusione tra GitLab e GitHub, è bene specificare come il secondo sia nato per ospitare progetti – naturalmente sviluppati con Git – a pagamento nel caso siano privati e gratuitamente se open source. GitLab è invece un prodotto completamente free e disponibile in due modalità: self-hosted e SaaS.
La prima modalità consente di installare GitLab su un proprio server locale o su un servizio di cloud privato con pieno controllo della piattaforma e dei propri dati: è l’ideale per le aziende che necessitano di accedere esclusivamente e in ogni momento ai propri progetti, in quanto offre più sicurezza dagli attacchi esterni e maggiore velocità di accesso, data l’esclusività dell’utilizzo del server. Tale versione è totalmente gratuita.
La versione SaaS (Software as a Service, appoggiato a gitlab.com) risiede completamente in ambiente cloud, seppur con significative differenze rispetto agli altri servizi citati in precedenza (GitHub e BitBucket). Ad esempio troviamo un numero illimitato di repository privati senza limiti per numero di collaboratori su singolo progetto, oltre ad offrire continuous integration e continuous delivery (per contesti DevOps) e Container Registry (per gestire immagini Docker). A questo si aggiunge la presenza di Mastermost, una soluzione open source per la comunicazione in team, alternativa a prodotti come Slack.
In informatica DevOps (dalla contrazione dei termini Development e operations, inteso come deployment o rilascio) è una metodologia di sviluppo del software che punta alla comunicazione, collaborazione e integrazione tra sviluppatori e addetti alle operations dell'information technology. DevOps vuole rispondere all'interdipendenza tra sviluppo software e IT operations, puntando ad aiutare a sviluppare in modo più rapido ed efficiente prodotti e servizi software.
Nel prossimo numero andremo ad approcciare in pratica Git e GitLab, con un articolo-tutorial dedicato.

")