Ecco pregi e difetti del file system progettato da Sun, apprezzatissimo per le sue doti di affidabilità in ambito storage.
ZFS è un File System open source originariamente sviluppato da Sun Microsystems. Annunciato nel Settembre del 2004, fu implementato per la prima volta nella release 10 di Solaris (2006) sotto licenza CDDL (Common Development and Distribution License). Nasce come file system in grado di superare per dimensioni qualsiasi limite pratico di storage: caratteristica garantita dai 128 bit su cui è strutturato. Il nome originario era infatti “Zetta File System” a indicare la capacità di memorizzazione nell’ordine dei triliardi di bit, notevolmente superiore a quella dei classici sistemi a 64 bit.
Cerchiamo di capire insieme perché ZFS promette di risolvere molti dei problemi e dei limiti dei sistemi Raid tradizionali, offrendo un livello di protezione dei dati significativamente maggiore e una serie di funzionalità avanzate particolarmente interessanti, come la creazione di snapshot a livello di file system.
Perché scegliere ZFS
I normali file system sono in grado di gestire un solo disco fisico alla volta: per gestire dischi multipli bisogna utilizzare invece un dispositivo hardware (come un controller RAID) o un sistema software (come LVM).
ZFS invece è organizzato in modo profondamente diverso: gestisce a livello nativo sia i dischi sia i volumi, con soluzioni analoghe a quelle fornite dalle tecnologie RAID.
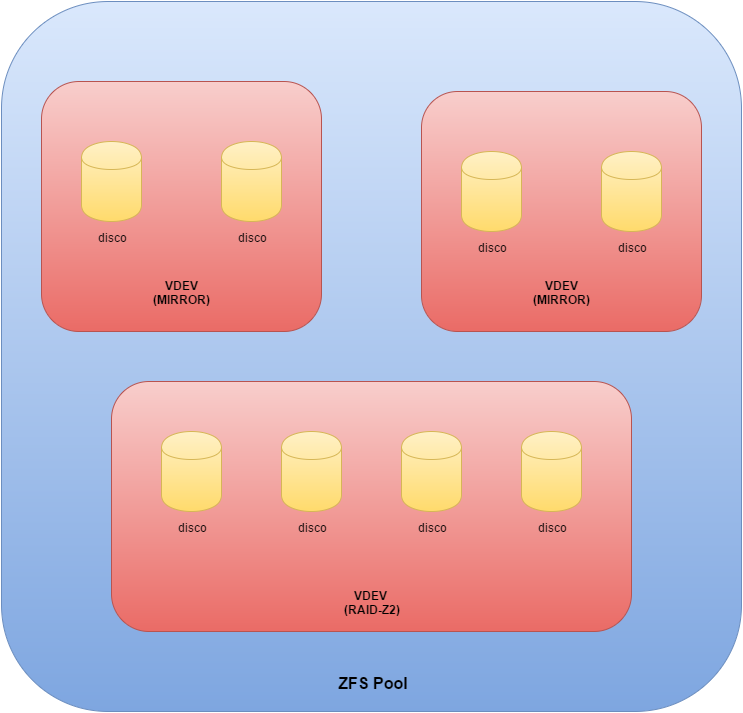
L’elemento base di ZFS sono i VDev (Virtual Device), che possono essere composti da uno o più hard disk fisici allocati insieme. Le configurazioni supportate sono nessuna parità (equivalente a JBOD, o RAID0 a disco singolo), mirror (equivalente al Raid 1), RAIDZ (equivalente a Raid 5), RAIDZ2 (equivalente a Raid6, doppia parità) e RAIDZ3 (equivalente a RAID6 con tripla parità).
Al livello superiore troviamo gli zpool, che altro non sono se non l’insieme di più Virtual Device allocati insieme. Spesso gli zpool sono associati al concetto di Volume nei file system tradizionali, per come è organizzato ZFS infatti, sono concretamente il contenitore in cui vengono memorizzati i dati.
Naturalmente esistono alcune limitazioni in questa struttura: i VDev infatti possono operare solamente all’interno di uno zpool e una volta definiti non possono essere espansi (se non sostituendo ogni singolo disco con uno più capiente). Al contrario, gli zpool possono essere estesi molto facilmente anche dopo la creazione aggiungendo altri VDev, ma – per come è strutturato ZFS – se anche uno solo dei Virtual Device presenti nel volume non è disponibile, l’intero blocco risulta irrimediabilmente compromesso.
I controller RAID generano dischi potenzialmente compatibili solo con controller identici (o dello stesso produttore) e – grazie ai metadati memorizzati sui dischi – riescono a ricomporre la configurazione di un volume logico anche su una macchina differente. Con ZFS non servono dispositivi hardware per ottenere questo risultato e i dischi possono essere migrati da una macchina fisica a un’altra senza perdita di dati, mantenendo anzi anche tutte le informazioni su Vdev e Zpool.
Integrità e affidabilità sono i pilastri del progetto ZFS, è infatti pensato per evitare nativamente la corruzione dei dati grazie a una serie di tecniche tra cui il checksum a 256 bit. Ad ogni operazione di scrittura il checksum viene ricalcolato e scritto insieme al dato sullo storage, operazione che viene replicata anche in fase di lettura. Naturalmente in caso di non corrispondenza viene rilevato un errore e – se sono disponibili dati ridondati – il sistema procede alla correzione.
L’utilizzo della tecnica Copy-On-Write è una ulteriore garanzia: cerchiamo di capire di cosa si tratta. Quando un dato viene sovrascritto dal sistema operativo, la nuova copia è memorizzata in un blocco differente e i metadati vengono aggiornati per puntare alla nuova posizione solo alla fine dell’operazione. In questo modo, in caso di problemi (ad esempio uno spegnimento improvviso) l’intero contenuto dei blocchi originali rimane perfettamente conservato nella posizione iniziale con una perdita limitata alle ultime informazioni che erano pendenti prima dell’interruzione anomala.
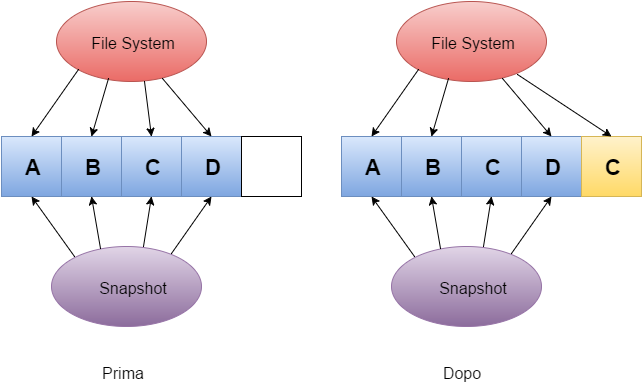
Una funzione utilissima di ZFS sono anche gli Snapshot, disponibili come funzione nativa del file system: si tratta di una fotografia dei dati a un preciso istante, particolarmente semplice e praticamente indolore proprio grazie al citato meccanismo Copy-On-Write.
ZFS si occupa anche di proteggere i dati dai cosiddetti “errori silenti” del disco, che possono essere causati da bug del firmware e malfunzionamenti dell’hardware, piuttosto che cavi difettosi. Con i file system tradizionali nonostante si verifichi un errore fisico del disco (e dunque una corruzione dei dati) non viene rilevato alcun errore. Per ovviare a questi problemi, ZFS utilizza un approccio all’integrità dei dati di tipo End-to-end: supera il limite dei checksum classici (che vengono memorizzati insieme al dato che descrivono), attraverso una struttura ad albero in cui i dati di controllo di ogni blocco “figlio” sono memorizzati nel puntatore “padre” del blocco stesso. Ogni blocco dell’albero contiene dunque i checksum di tutti i suoi blocchi figli, separando così le informazioni di controllo dal dato che devono verificare.
Ad ulteriore garanzia della integrità dei dati memorizzati ZFS implemente un meccanismo detto Scrub: questa procedura va ad analizzare i dati presenti nello storage (ed eventualmente anche in memoria) e rileva e corregge eventuali errori utilizzando i dati ridondati.
ZFS prevede anche un sistema di cache a diversi livelli. I dati utilizzati con maggiore frequenza vengono tenuti in RAM e - in base alla frequenza di lettura/scrittura - possono essere mantenuti o spostati su SSD o dischi tradizionali.
Nello specifico, ZFS utilizza due differenti tipi di cache in lettura e uno in scrittura: rispettivamente ARC e L2ARC (Level2 - Adaptive Replacement Cache) e ZIL (ZFS Intent Log).
ARC funziona utilizzando quattro liste di elementi. Nella prima (MRU – Most Recently Used) si trovano gli elementi utilizzati più di recente organizzati in ordine cronologico, mentre nella seconda (MFU – Most Frequently Used) si trovano quelli utilizzati con maggior frequenza. Per ognuna delle due liste è presente anche una copia-ombra necessaria per evitare che elementi rimossi in precedenza dalla cache vengano reinseriti nella lista. Questa funzione è utile nelle situazioni in cui oggetti utilizzati solo occasionalmente vadano a occupare inutilmente aree di memoria ad accesso rapido.
Per la cache ARC di secondo livello la soluzione più utilizzata sono le unità flash, in quanto offrono un buon compromesso prestazionale tra la velocità della RAM e quella dei dischi meccanici. L’utilizzo di L2ARC è opzionale, ma può aiutare molto a migliorare le prestazioni in lettura, oltre a contribuire significativamente nelle operazioni di deduplica.
ZIL si occupa invece di accelerare le transazioni sincrone appoggiandosi a storage di tipo SSD per ridurre le latenze in scrittura verso dischi classici. Tuttavia solo i carichi di lavoro sincroni (ad esempio scritture verso database) possono beneficiare di questa funzionalità, mentre le normali operazioni di scrittura come la copia di file non si appoggiano a questa cache.
La deduplica dei dati è un’altra importante funzionalità - implementata in ZFS a partire dal 2009 - che permette di identificare ed eliminare le copie ripetute di dati presenti nello storage e viene anche indicata come tecnica di storage a singola istanza. L’obiettivo principale è quello di ottimizzare l’utilizzo dello spazio di memorizzazione, e trova maggiore utilità naturalmente nelle situazioni in cui sono presenti grandi quantità di dati duplicati, come accade ad esempio nei backup repository. La deduplica richiede però una quantità davvero significativa di RAM ed è in generale sconsigliata dove le prestazioni siano particolarmente importanti. Con ZFS si parla di una quantità di Ram minima che varia da uno a cinque GByte per ogni Terabyte di dati. La situazione può poi variare da caso a caso e richiede una analisi del pool con gli strumenti forniti dallo stesso Zfs per avere un valore più attendibile della Ram effettivamente necessaria.
La possibilità di ottimizzare l’utilizzo dello spazio, può risultare molto utile nel caso si vogliano spostare dati attraverso una rete (sia essa locale o Internet). ZFS permette infatti di inviare e ricevere snapshot del file system per implementare la replica remota: lo stream inviato rappresenta l’intero stato del sistema in un momento specifico. Le sincronizzazioni successive alla prima sono effettuate in modo estremamente efficiente andando ad agire solo sui dati che hanno effettivamente subito variazioni.
I rischi di ZFS
Abbiamo visto che, per come è strutturato ZFS, la soluzione migliore per implementarlo è lasciare che sia il file system a occuparsi della struttura logica dei volumi e della ridondanza. Gli eventuali controller RAID hardware presenti sull’host diventano di fatto non necessari se non per il collegamento fisico dei dischi. Le schede che non dispongono di una modalità JBOD (Just a bunch of disks) potrebbero renderne difficile l’utilizzo, anche se si sceglie ad esempio di configurare ogni singolo disco come un volume RAID 0. Per collegare i dischi può bastare una scheda HBA (Host Bus Adapter). Chi volesse adottarlo con un controller LSI o un controller LSI rimarchiato (come la quasi totalità delle IBM/Lenovo ServeRaid, DELL PERC e Fujitsu) può intervenire (a suo rischio e pericolo) facendo un crossflash di questi controller nella versione IT (Initiator/Target) mode. Questo naturalmente pone un limite significativo all’hardware che può essere adottato. Diventa di fatto inutile anche la cache onboard dei controller – sempre presente in particolare sui server di fascia più alta. Per fare in modo che ZFS lavori correttamente è consigliato disabilitarla per consentirgli l’accesso diretto agli hard disk.
Anche la scelta della giusta configurazione RAID è un punto importante nella realizzazione di una architettura di storage su ZFS, sono infatti tre i possibili vantaggi che si possono sfruttare: capacità, prestazioni o integrità.
Per quanto riguarda la capacità, il parametro da considerare è quello che viene definito Storage (o Space) Efficiency, ovvero il rapporto tra la capacità grezza dei supporti fisici utilizzati e quella di storage effettivamente disponibile una volta applicate ridondanza e parità.
Analizzando le opzioni offerte da ZFS si può calcolare questo parametro in base ai dischi a disposizione usando uno dei numerosi tool disponibili online. Con il potente strumento di Wintelguy.com (http://wintelguy.com/raidcalc.pl) si può ad esempio confrontare l’efficienza di un Raid tradizionale rispetto a ZFS. In ogni caso basta sfogliare qualche forum per capire chiaramente che l’unica soluzione che garantisce un buon livello di protezione, che è adatta anche ai dischi che superano il Tbyte di dimensione e che garantisce un tempo di resilvering basso (anche con le implementazioni Open di ZFS) è la modalità Mirror, nonostante questo riduca di fatto l’efficienza al 50%. Le cose cambiano naturalmente quando si parla di sistemi di storage con svariate decine se non centinaia di Tbyte, in cui l’architettura del sistema è stata considerata con attenzione da professionisti che ben conoscono limiti e potenzialità di ogni soluzione. La soluzione meno affidabile resta invece la Raid-Z che permette sì di avere un’efficienza più elevata, ma a costo di una protezione molto più bassa, soprattutto durante la fase di resilvering in cui i dischi sono sottoposti a un notevole stress.
Un altro potenziale problema di ZFS riguarda la necessità – non effettiva, ma pratica – di utilizzare un sistema con RAM ECC. ZFS naturalmente può funzionare su un PC o Server che non ha moduli ECC, ma in questo caso l’integrità dei dati è messa in pericolo. Utilizzare RAM non ECC infatti potrebbe portare a situazioni in cui errori presenti in memoria (che non vengono rilevati e tantomeno corretti) vadano a corrompere i dati in modo irrimediabile.
Se il dato viene corrotto durante la permanenza nella memoria RAM, infatti, il checksum calcolato prima di essere scritto sul pool risulta sbagliato in partenza e perde di qualsiasi tipo di utilità al fine dell’integrità dei dati. Un ciclo di letture/scritture o uno scrub in situazioni come questa può portare a un danneggiamento dell’intero pool.
A causa dell’incompatibilità tra la licenza di tipo CDDL e GNU, il file system ZFS non può essere integrato e distribuito direttamente insieme al kernel Linux, tuttavia è possibile installarlo come modulo aggiuntivo ed è sempre più utilizzato anche su questa piattaforma, identificata abitualmente con la signa ZOL (ZFS on Linux). Tra i principali sistemi che supportano invece nativamente ZFS troviamo Open Solaris, FreeBSD e OpenIndiana (lista completa disponibile qui).

")