Here’s qualities and flaws of the file system developed by Sun, highly appreciated for its reliability in the storage sphere.
ZFS is an open source File System originally developed by Sun Microsystems. Announced in September 2004, it has been implemented for the first time in the release 10 of Solaris (2006) under the CDDL License (Common Development and Distribution License). It was born as a file system capable of overcoming in dimensions the practical storage limit: this feature is because of the 128-bit architecture. The original name was “Zetta File System” indeed, to indicate the storage capacity in the order of a trilliard (10^21) bits, way higher than classic 64-bit systems.
Let’s try and understand together why ZFS promises to solve several of the problems and limits of traditional Raid systems, offering a significantly higher level of data protection and a series of particularly interesting advanced features, like creating snapshots on a file system level.
Why choosing ZFS
Common file systems can manage only one single disc at time: managing multiple disks requires an hardware device (like a RAID controller) or a software system (like LVM).
ZFS instead is designed in a profoundly different manner: it natively manages both disks and volumes, with solutions similar to those provided by RAID technologies.
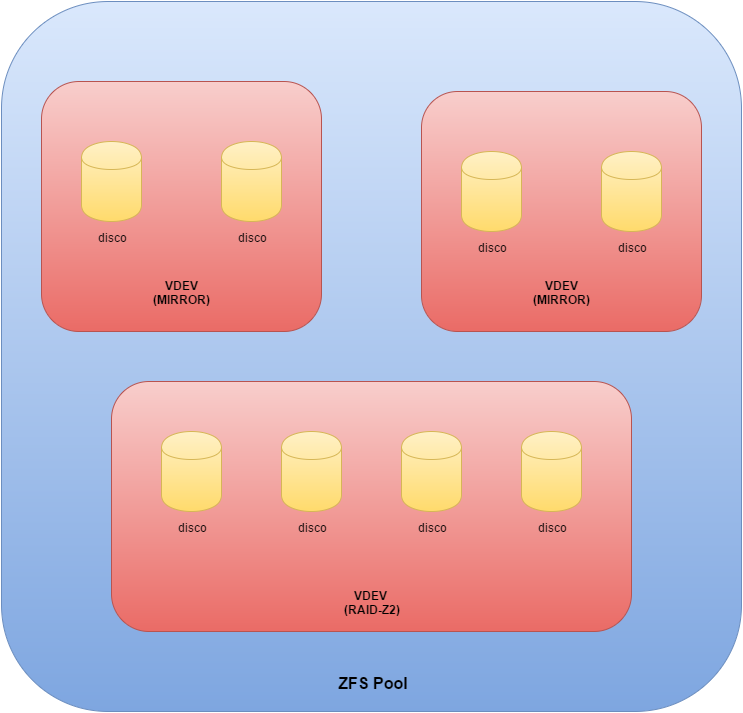
The basis elements of ZFS are VDevs (Virtual Devices), which can be composed by one or more physical hard disks allocated together. Supported configurations include no parity (the equivalent of JBOD, or single disk RAID 0), mirror (RAID 1), RAID-Z (RAID 5), RAID-Z2 (RAID 6, double parity) and RAID-Z3 (RAID6 with triple parity).
At the upper level we find zpools, which are several VDev allocated together. Often zpools are associated with the idea of Volume in traditional file systems and, as ZFS is actually organized, they are the actual block where data is stored.
Naturally this structure brings some limitations: VDev indeed can operate only inside a zpool and can’t be expanded once created, albeit a disk swap with a larger one does the job. On the other hand, zpool can be easily expanded even after creation by adding other VDevs, but -due to the structure of ZFS- if even only one of the Virtual Devices inside the volume is not available, then the whole block is definitely compromised.
RAID controllers generate disks potentially compatible only with identical controllers (or at least by the same manufacturer) and -thanks to metadata present on disks- can replicate the configuration of a logical volume also on a different machine. No hardware devices are needed with ZFS in order to achieve this results, and disks can be migrated from a machine to another without any loss of data, yet maintaining all the information about VDev and zpool.
Integrity and reliability are the pillars of the ZFS project, which was indeed planned to avoid data corruption thanks to several technologies, with a 256-bit checksum amongst them. Checksum is calculated again and written with the piece of data on the storage at each writing and reading operation. Obviously if there’s a mismatch an error is raised and -if redundant data is available- the system performs a correction.
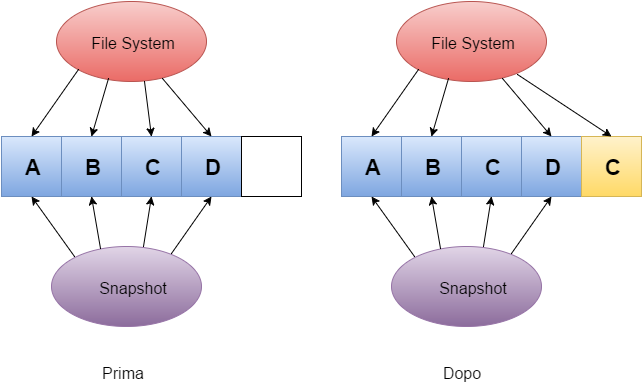
The use of the Copy-On-Write technique is an added guarantee: let’s try to understand what it’s about. When a piece of data is overwritten by the operating system, the new copy is stored on a different block and metadata is updated to point to the new position only once the operation is over. In this way, in case of problems like a sudden power-off, the whole content of the original blocks is perfectly stored in the initial position with a limited loss regarding the latest information that were waiting to be written before the unexpected interruption.
 Snapshots before and after
Snapshots before and after
Snapshots, which are natively available, are a very useful feature of ZFS: a snapshot is a ‘’picture’’ of data in a precise instant, particularly simple and actually painless thanks to the aforementioned Copy-On-Write mechanism.
ZFS also protects data against “silent error” of the disk, which can be caused by bugs of the firmware and malfunctions of the hardware, or even bad cables. With traditional file systems no error is raised in case of a disk’s physical error, with subsequent loss of data. To solve this situation ZFS uses an End-to-End approach on data integrity: the limit of classic checksums (that is, being stored WITH the piece of data they refer to) is overcome using a tree structure where the control data of each “son” is stored with the pointer of the “father” of the block itself. Each block thus contains the checksums of all its sons, separating control information from the piece of data they refer to.
To add a further guarantee on the integrity of stored data, ZFS implements a mechanism called Scrub: this procedure analyzes data on the storage (and, if any, on memory) and identifies and corrects any error using redundant data.
ZFS also offers a layered caching system. Data being more frequently used is also stored on RAM and, according to the writing/reading frequency, can be kept or moved on SSDs or traditional disks.
Going deeper, ZFS uses two different reading caches and one in writing: ARC and L2ARC (Level2 - Adaptive Replacement Cache) and ZIL (ZFS Intent Log) respectively.
ARC uses 4 lists of elements. The most used elements are organized in chronological order in MRU (Most Recently Used), then the ones used with greatest frequency are in MFU (Most Frequently Used). Each of these two lists has a shadow-copy required to avoid that the elements previously deleted from the cache are inserted again in the list. This feature comes handy in situations where barely used objects uselessly occupy quick access memory areas.
The most used solution for second level ARC cache are flash units, as they offer a good performance compromise between the speed of RAM and mechanical disks. The use of L2ARC is optional, yet it can greatly help to improve reading performances, in addition to add significant value to deduplication operations.
ZIL instead is about accelerating synchronous transaction leveraging SSD storages to reduce writing latencies towards classic disks. However only synchronous workloads (for instance, writing to databases) can take advantage of this features, while regular writing operations -like copying files- don’t leverage this cache.
Data deduplication is another important feature, implemented in ZFS in 2009 for the first time, which identifies and deletes repeated copies of the same piece of data present on the storage, also knowns as single instance storage technique. The main goal is to optimize the storing space usage, and brings the greatest benefits, obviously, in situations with great amounts of duplicated data, for instance backup repositories. Dedup however requires a very large amount of RAM and, in general, it’s a discouraged practice when performances are very important.
ZFS requires at least one to five GByte of RAM for each TByte of data; the amount can vary according to cases and generally requires an analysis of the pool with the tools provided bt ZFS itself in order to have a more reliable value of needed RAM.
The opportunity of optimizing the use of space can be very useful should you have to move data on a network (local or Internet). ZFS indeed allows to send and receive file system snapshots to implement the remote replication: sent stream represents the entire state of the system in a specific moment. Synchronizations after the first one are performed in a very efficient way as they operate only on data that have actually been modified.
Risks with ZFS
We have seen that, because of the structure of ZFS, the ideal solution to implement it is to let the file system to manage the logical structure of volumes and redundancy. Any hardware RAID controller get, as a matter of fact, unnecessary, except for the physical disk connection. Controllers that don’t have a JBOD mode (Just a Bunch Of Disks) might make the implementation quite hard, even if each single disk is configured as a RAID 0 volume. To connect disks you can use an HBA card (Host Bus Adapter). Those who want to use ZFS with an LSI controller or a rebranded LSI controller (like most IBM/Lenovo ServeRaid, DELL PERC and Fujitsu) can do a crossflash -at his own peril!- of the IT (Initiator/Target) mode versions. This adds a significant limitation on the hardware that can be adopted. The onboard controller’s cache -always available on high end servers- gets unuseful too. It’s advised to disable it and let ZFS directly access hard disks, in order to make it work properly.
The choice of the proper RAID configuration is an important point in the realization of a storage architecture based on ZFS; indeed, there are 3 advantages that can be exploited: capacity, performances and integrity.
Speaking about capacity, the parameter to be taken into account is the one defined as Storage (or Space) Efficiency, that is, the ratio between the raw capacity of physical devices and the effective available storage capacity once redundancy and parity are applied.
By analyzing the options offered by ZFS, you can calculate this parameter according to the available disks with an online tool. You can use, for instance, the powerful tool by Wintelguy.com (http://wintelguy.com/raidcalc.pl) to compare the efficiency of a traditional RAID with ZFS. In any case, you need to check a few online forums to clearly picture that the only solution that guarantees a good level of protection and a low resilvering time (even with the open implementations of ZFS) and it’s also suitable for disks exceeding the TByte dimension is Mirror mode, despite reducing efficiency, as a matter of fact, by 50%. Things change when we talk about storage systems with tens or even hundreds of TByte, where system architecture is carefully considered by professionals that know very well the limits and potentialities of every solution. The least reliable solution is RAID-Z, offering an higher efficiency but a lower protection level, in particular during resilvering where disks undergo a great stress.
Another potential problem in ZFS is the need -not effective, rather practical- of using a system with ECC RAM. ZFS works also on a PC or server without ECC modules, but in this case data integrity is at risk. Using non-ECC RAM might lead towards situations where errors on the memory (which are neither identified nor corrected) can corrupt data irremediably.
If a piece of data is corrupted during its permanence in RAM, indeed, the checksum that is calculated before being written on the zpool is wrong and loses all it usefulness about data integrity. The reading/writing cycle of a scrub in such situations can bring to a damage of the whole zpool.
Because of the incompatibility of the CDDL license and GNU, the ZFS file system can’t be integrated and distributed with the Linux kernel, however it can be installed as an additional module and gets more and more used on this platform, usually identified with ZOL (ZFS On Linux). Among the main systems that natively support ZFS we can find Open Solaris, FreeBSD and OpenIndiana (a complete list is here available).

")