La risoluzione rapida dei problemi è un'attività fondamentale per qualsiasi sistemista. Vediamo alcuni trucchi e suggerimenti per diventare più bravi e rapidi nel diagnosticare e risolvere i malfunzionamenti di un sistema Linux.
Nei precedenti numeri di GURU advisor abbiamo già dedicato un articolo ai comandi utili per il troubleshooting di base in ambiente Linux nel contesto della guida alle VPS, ma quando Top, PS e netstat non bastano più, bisogna rivolgersi a strumenti più avanzati. Il troubleshooting è una attività che può facilmente portare a sprechi di tempo e risorse, proporzionali alla difficoltà del problema che si sta cercando di risolvere. Per massimizzare il risultato e limitare tentativi e prove inutili è necessario agire seguendo procedure ben strutturate.
![]()
Il metodo USE – acronimo di Utilization, Saturation, Errors – è stato ideato da Brendan Gregg (autore tra gli altri di un libro sul tema: Systems Performance - Prentice Hall, 2013) e si basa su un’idea semplice quanto efficace: definire un workflow che determini il grado di utilizzo, saturazione ed eventuali errori presenti per ogni risorsa disponibile. In questo modo si restringe gradualmente il campo dei possibili fattori scatenanti, fino ad arrivare ad identificare in modo preciso la causa del calo di prestazioni del sistema.
La definizione delle risorse è piuttosto facile, si tratta infatti dei componenti fisici della macchina (possiamo applicare il metodo anche ai componenti software, ma diventerebbe molto complicato e dettagliato, forse anche troppo visto lo scenario), un server nel nostro caso, e ovviamente anche per la controparte virtuale. Processore, memoria, disco, controller, interfaccia di rete, bus, etc. Naturalmente una maggiore conoscenza della architettura porta a una maggiore velocità e precisione nell’identificazione del problema, seppur implicando una complessità e una curva di apprendimento non indifferente.
Normalmente l’analisi a livello di macro-componenti hardware (processore, memoria etc. senza scendere a maggiori livelli di dettaglio) e che escluda l’ambiente software - per via delle numerose e elevate difficoltà aggiuntive che introdurrebbe - è sufficiente nella applicazione pratica della tecnica USE.
La definizione di utilizzo, saturazione ed errore è un piuttosto sottile, tuttavia per dare delle definizioni standard possiamo dire che: per utilizzo s’intende la proporzione d’uso di una risorsa, fissati gli estremi a 0% (risorsa non in uso) e 100% (la risorsa non può accettare ulteriore lavoro senza introdurre latenza o code), mentre per saturazione si intende il grado di lavoro che la risorsa non è in grado di eseguire (e che quindi rimane quindi in coda o introduce latenza. Notare come utilizzo e saturazione siano strettamente correlati). Per la definizione di errore, ci si riferisce al comune significato del termine.
Tool disponibili per risorsa
Come insegna il metodo USE, il lavoro di ricerca e risoluzione dei problemi si deve basare sull’analisi dello stato delle varie risorse del sistema attraverso specifici strumenti. L’osservazione complessiva deve servire solo nella fase iniziale, per farsi una prima idea delle modalità di azione. Il sistema operativo Linux offre svariati tool di diagnostica nativi, a cui possono esserne affiancati altri molto utili, ad esempio installando il pacchetto sysstat che li rende disponibili da linea di comando. Naturalmente la modalità dettagliata di installazione e la disponibilità di questi ultimi dipenderà dalla distribuzione Linux in uso.
uptime [Load Average]

Uptime è il componente che fornisce informazioni sul load average (ovvero la media del lavoro computazionale svolto dal sistema) degli ultimi 1, 5 e 15 minuti. Il load average tiene in considerazione sia i processi che sono in stato runnable (quindi che stanno utilizzando la CPU o sono in coda per essere elaborati), sia non-interruptable (ovvero in coda per un accesso I/O, ad esempio lettura dati del disco). Una casistica di esempio in cui il load average risulti elevato anche a processore scarico, si ha quando il collo di bottiglia è lato storage (share di rete lenta, disco difettoso, periferiche USB con prestazioni scarse etc.) e porta ad avere numerosi processi in stato uninterrutable sleep in attesa della periferica.
Il numero che viene restituito deve però essere rapportato al numero di core presenti sulla macchina: un valore di uptime inferiore alla quantità di core indica una situazione priva di problemi (il sistema è in grado di gestire il carico di lavoro senza affanni), mentre un valore superiore indica uno stato di sovraccarico o saturazione (che può essere più o meno temporaneo).
Nell'esempio mostrato all'inizio del paragrafo viene rilevato il load average durante uno stress test particolarmente importante con un tool dedicato: nell'ultimo minuto è pari addirittura a 42, che significa che servirebbero altre 38 CPU per eseguire il carico di lavoro mantenendo il sistema non sovraccarico. Terminato il test, la macchina a regime mostra un valore decisamente più basso (0.13, è quasi in idle).
dmesg -T | tail [errori del kernel]
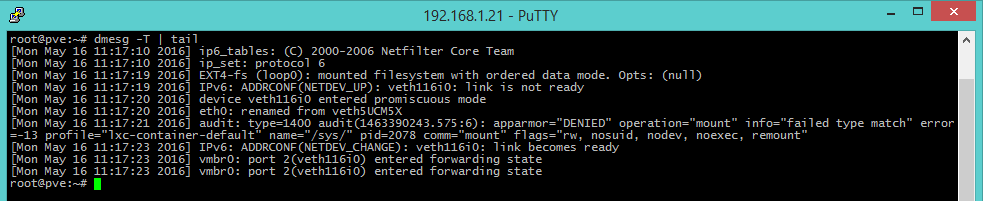
Dmesg è il comando che permette di visualizzare nel terminale il buffer del kernel contenente gli errori. Concatenandolo al comando tail è possibile visualizzare in modo facilmente consultabile gli ultimi 10 messaggi di sistema (collegamento periferiche, segnalazione errori, interrupt etc.), che possono fornire indizi utili sulle cause del degrado prestazionale.
vmstat [memoria virtuale e informazioni dettagliate]

I due comandi precedenti forniscono risultati piuttosto generici sullo stato del sistema, vmstat invece è molto dettagliato: fornisce informazioni su processi, memoria, paging, block I/O, attività disco e CPU. Il comando lanciato senza argomenti opzionali restituisce tutte le informazioni collezionate dall’ultimo avvio della macchina, mentre l’aggiunta del parametro “1” indica di aggiornare le informazioni ogni secondo. Per interrompere l’output a schermo bisogna digitare ctrl+C. La visualizzazione nel terminale è piuttosto schematica, l’output è organizzato in gruppi di colonne, ognuno riguardante una specifica area del sistema (processi, memoria, swap, I/O etc). Le singole colonne invece indicano rispettivamente:
- r : è il numero di processi attivi e in coda su ogni CPU ed è un indicatore migliore rispetto ai carichi medi trovati col comando Uptime, dato che non include richieste I/O. Un numero ‘r’ maggiore del numero delle CPU indica saturazione.
- free: indica la memoria libera (idle) in kilobyte. Il comando free -m fornisce ulteriori informazioni.
- si, so: rispettivamente swap-in e swap-out, se sono diversi da zero, la memoria sta operando sull’area di swap su disco.
- us, sy, id, wa, st: sono parametri riferiti al tempo di CPU, fatta la media su tutte le CPU. Si riferiscono rispettivamente, a user time (tempo occupato ad eseguire codice non proveniente dal kernel), system time (tempo occupato ad eseguire codice del kernel), tempo di idle, tempo speso aspettando una richiesta IO e tempo ‘rubato’ (stolen) da una macchina virtuale.
La somma dei tempi us + sy indica se una CPU è sovraccarica e un numero costante di wa indica un collo di bottiglia causato dal disco: in questo caso il processore è a riposo perché i task sono in attesa di un’operazione I/O del disco che non arriva. Per ottenere informazioni più dettagliate delle diverse aree del sistema, si possono utilizzare alcuni comandi aggiuntivi.
mpstat -P ALL 1 [stato CPU]
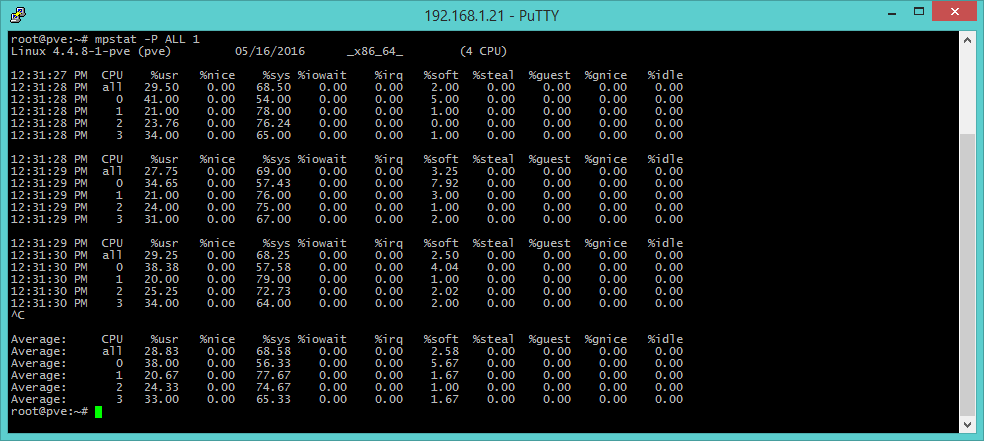
Il comando mpstat integra e completa le informazioni sui processori, fornendo informazioni dettagliate sulle attività di ciascun core disponibile (opzione -P ALL) (in modo istantaneo se non si aggiungono argomenti, ogni N secondi se indicato un argomento numerico). I campi da tenere in considerazioni sono usr (percentuale di esecuzione a livello utente), sys (percentuale a livello di kernel), iowait (tempo di idle speso aspettando le richieste I/O), guest (tempo speso per processori virtuali) e infine idle (tempo il processore era in idle e il sistema non aveva richieste di I/O disco).
pidstat [processi]
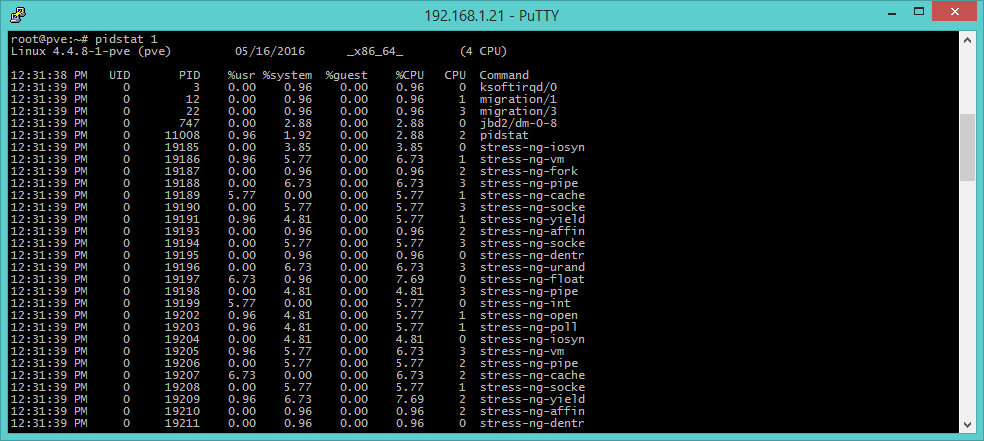
Il comando pidstat fornisce informazioni sui processi attivi gestiti dal kernel e il parametro 1 –come avviene per gli altri comandi già descritti – indica il tempo in secondi intercorsi tra un report e l’altro. L’output è molto simile a quello ottenuto con il comando top, ma la visualizzazione è strutturata in tabelle istantanee, piuttosto che in un elenco continuo di report. In questo modo è possibile investigare sui pattern che si ripetono nel tempo, oltre che a poter appuntare a parte i risultati con copia-e-incolla.
iostat -xz [I/O disco]
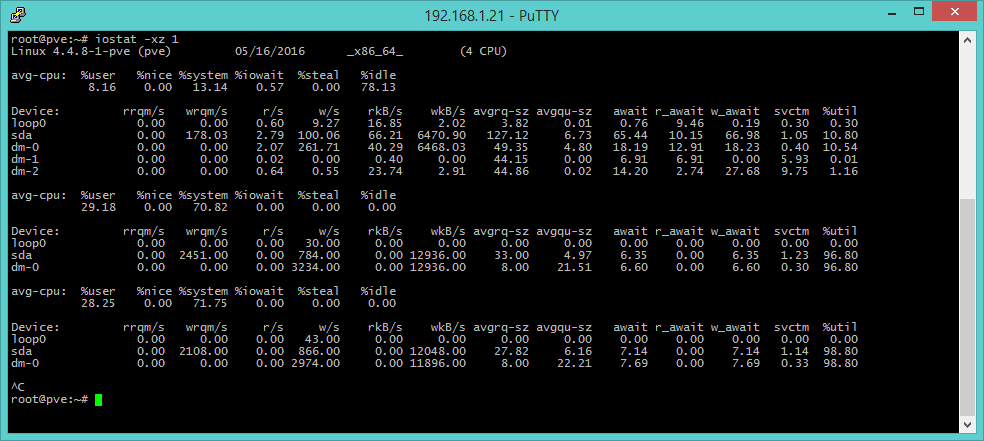
iostat fornisce informazioni sui dispositivi a blocchi (dischi), utili per comprendere i carichi di lavoro eseguiti e le prestazioni risultanti dei sistemi di I/O. Nella parte superiore dell’output video sono riportati alcuni parametri riferiti al processore, ma l’area che racchiude le informazioni più importanti è quella immediatamente successiva in cui si trovano rispettivamente le colonne:
- r/s, w/s, rkB/s, wkB/s: indicano valori riguardanti operazioni di lettura, scrittura, Kbyte letti e Kbyte scritti per secondo dal dispositivo. Sono utili indicatori del carico di lavoro. Cattive prestazioni possono dipendere da un carico eccessivo.
- await: indica il tempo che penalizza l’applicazione e include sia il tempo di coda che il tempo di utilizzo. Valori superiori a quelli aspettati indicano saturazione o problemi al dispositivo.
- avgqu-sz: indica la media delle richieste inviate al dispositivo. Valori maggiori di 1 possono indicare saturazione, sebbene bisogna tener conto che alcuni device possono operare sulle richieste in parallelo, in particolari dispositivi virtuali che si appoggiano su diversi dischi di back-end.
- %util: indica la percentuale di utilizzo del dispositivo: un valore maggiore di 60 è segnale di cattive prestazioni, mentre il valore 100 indica la saturazione, come nel caso in cui un singolo I/O acceda in modo continuo e prolungato alla stessa risorsa.
L’argomento -x serve per mostrare informazioni estese, mentre l’opzione -z permette di escludere i dispositivi su cui non c’è alcuna attività, per una migliore e più semplice consultazione dell’output. Da sottolineare che iostat non funziona su container OpenVZ/Virtuozzo.
free –m [memoria]

Il comando free visualizza diverse informazioni sullo stato di utilizzo della memoria RAM, l’aggiunta del parametro –m specifica l’unità di misura in Megabyte.
Attenzione però perché una analisi superficiale dei risultati visualizzati può portare a una errata interpretazione del loro significato. I valori di used e free – che si trovano come intestazione delle colonne – possono essere fuorvianti in quanto indicano, ad esempio nel caso della memoria occupata, la somma di memoria effettivamente in uso sommata a quella riservata come buffer (per le operazioni di I/O). La memoria riservata a buffer infatti, è effettivamente a disposizione del sistema, seppur “pre-allocata”. I valori effettivi di utilizzo si trovano alla seconda riga, quella identificata dal campo -/+ buffers/cache.
Per portare un esempio pratico, un valore alto di buffers indica problemi a livello I/O (indagabili in modo approfondito con iostat). Il valore used alla riga Swap indica se e quanto il sistema stia effettuando lo swap su disco. Alcune situazioni particolari, come i sistemi che usano il file system ZFS, mostrano risultati ancora più imprevedibili, dato che implementano un sistema di cache via RAM.
sar -n DEV 1 [I/O rete]
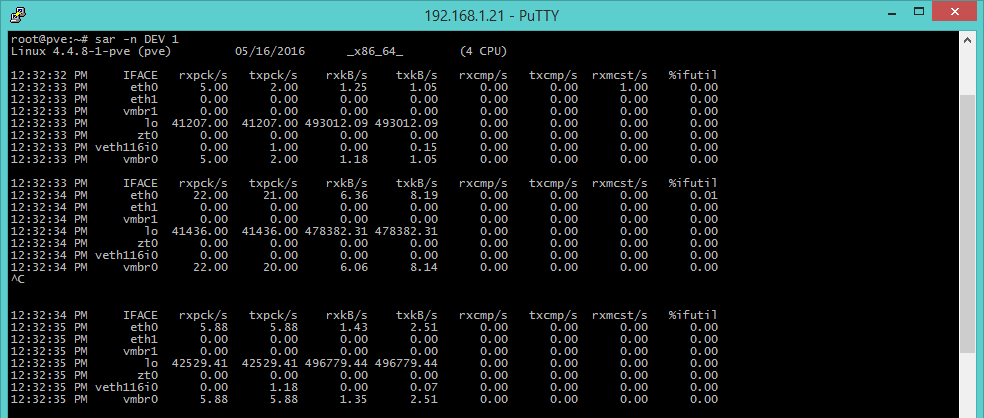
Fin qui abbiamo visto strumenti che permettono di controllare le risorse di calcolo, fondamentalmente processore, disco e memoria. Ma spesso è necessario valutare lo stato di funzionamento delle connessioni di rete, in questo ambito si posiziona il comando sar. Questo tool mostra le statistiche sul throughput delle interfacce di rete: rxpck/s e txpck/s (pacchetti ricevuti e trasmessi per secondo), rxkB/s e txkB/s (kilobyte ricevuti e trasmessi per secondo), %ifutil (percentuale d’uso dell’interfaccia). Questo ultimo parametro rappresenta la somma dei kB inviati e ricevuti per secondo, espressa come percentuale sulla velocità dell’interfaccia in caso di half-duplex. In caso di interfaccia full-duplex, il parametro da considerare è il maggiore di rxkB/s e txkB/s.
sar -n TCP,ETCP 1 [connessioni TCP]
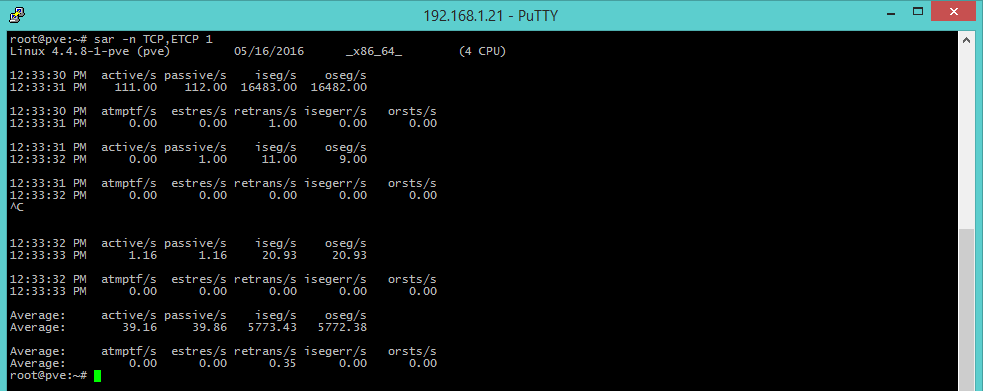
Le opzioni TCP e ETCP (ErrorTCP) offrono delle metriche legate alle connessioni TCP avviate per secondo (active/s), accettate (passive/s) e alle ritrasmissioni per secondo (retrans/s). Il numero di connessioni iniziate/accettate offrono una misura di massima del grado di utilizzo del server, mentre un alto indice di ritrasmissioni indica un problema lato server o sulla rete: ad esempio la situazione in cui il server è sovraccarico e non accetti più pacchetti, o la connessione ad Internet non sia stabile.
atop [panoramica generale]
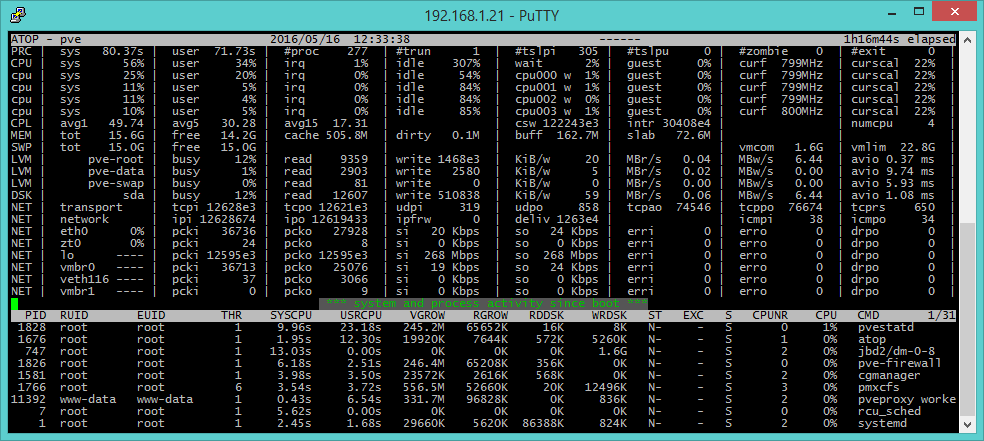
Atop (versione evoluta del comando top) fornisce una panoramica complessiva del sistema. L’output a terminale è organizzato in due parti: quella superiore che fornisce informazioni a livello di sistema, mentre quella inferiore si riferisce ai singoli processi. Essendo un tool di diagnostica complessiva, alcune informazioni sono le stesse fornite anche da altri comandi visti in precedenza. Ad esempio avg1, avg5 e avg15 di CPL (CPU Load) sono le stesse medie relative al carico degli ultimi 1, 5 e 15 minuti visbili con uptime. Si possono ottenere ulteriori informazioni sui processi utilizzando alcuni tasti dedicati: m (informazioni sull’uso della memoria), d (disco), n (rete -- occorre installare il modulo netatop http://atoptool.nl/downloadnetatop.php), c (linea di comando), v (caratteristiche dei processi,) u (attività per utente) e g (generic, è l’output di default). La pressione del tasto r permette di aggiornare la schermata.
Tra le funzionalità di atop troviamo il logging (solitamente sono in /var/log/atop/), che rende possibile l’analisi delle performance anche in momenti passati (funzione non possibile con top), possibilità non offerta da top.
Inoltre atop raccoglie informazioni sui processi in un modo tale che quasi ogni processo viene identificato, mentre top ha un sistema che perde diversi processi a vita breve che possono contribuire alla maggior parte dell'utilizzo delle risorse in certe situazioni.
In questo articolo abbiamo introdotto la tecnica USE e analizzato una serie di strumenti specifici per effettuare il troubleshooting in ambiente Linux. Con questi strumenti è possibile individuare con un buon livello di precisione le cause dei cali di performance, oltre a poterli utilizzare anche per le attività di manutenzione ordinaria e monitoraggio della macchina.

")