
Alta disponibilità con vSphere HA
Il servizio vSphere HA, ovvero vSphere High Availability, attivabile all’interno di un cluster, può intervenire in caso di blocco di host, di sistemi operativi guest, di applicazioni in esecuzione sulle VM. In caso di blocco di un host, viene eseguito un riavvio automatico delle macchine virtuali su un altro host. In caso di blocco di un sistema guest, viene riavviata la relativa VM; in caso di blocco di un’applicazione, sfruttando software di terze parti (con un “agent” in ascolto), viene riavviata la relativa VM. Ovviamente non è detto che il riavvio di una VM risolva un problema sul sistema guest; sarà cura dell’amministratore configurare HA al meglio ed in base alle proprie esigenze.
Per il funzionamento di vSphere HA è necessario rispettare alcuni limiti.
- È necessario che il cluster non superi 32 host.
- All’interno del cluster non si possono avere più di 4000 VM.
- Ogni host non può avere più di 512 VM (indipendentemente dal numero di host/cluster).
vSphere HA è integrato con vSphere DRS: infatti se un host subisce un blocco e le VM vengono spostate su un altro host, DRS può intervenire per bilanciare i carichi.
vSphere HA richiede il vCenter Server solo per la configurazione iniziale. In seguito il servizio funzionerà sugli host in maniera indipendente dal vCenter. Quest’aspetto è importante nel caso in cui si volesse proteggere un’istanza virtuale di vCenter Server con vSphere HA: se l’host che ospita il vCenter dovesse subire un improvviso blocco operativo (con la conseguenza di avere il vCenter non in linea), vSphere HA sposterebbe il vCenter su un altro host.
Architettura di vSphere HA
Il servizio HA si abilita all’interno di un cluster (vedere più avanti la sezione “Attivazione e configurazione di vSphere HA”). Appena il servizio HA viene abilitato, su ogni host entra in funzione il servizio Fault Domain Manager (FDM): grazie a questo servizio, ogni host ha “coscienza” di esser parte di un “fault domain”. Affinché un host possa far parte di un fault domain, è necessario che siano rispettate 3 condizioni:
- l’host non deve essere disconnesso dal vCenter Server;
- l’host non deve trovarsi in maintainance mode;
- l’host non deve trovarsi in stand-by mode.
Il fault domain è gestito da un host “master”; tutti gli altri host sono definiti “host slave”. L’elezione del master host avviene tramite un processo che premia l’host che accede al numero più alto di datastore. Se più host hanno lo stesso numero di datastore, la scelta si basa sul MOID (Managed Object ID), ossia un identificativo assegnato dal vCenter Server. L’elezione dura circa quindici secondi e occorre ogni volta che:
- si abilita il servizio HA;
- il master host presenta problemi dopo essere stato impostato in maintainance mode, standby mode o dopo la riconfigurazione di HA;
- gli host di tipo slave non comunicano più con il master per problemi di rete.
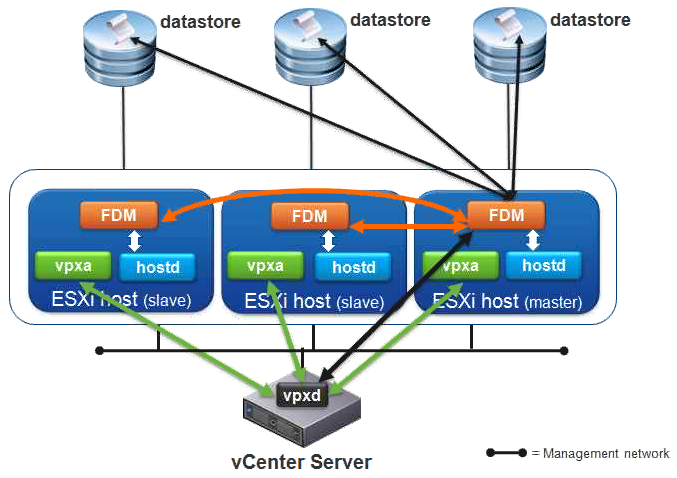
Durante il periodo di elezione la comunicazione avviene utilizzando il protocollo UDP (porta 8182). Terminata l’elezione, le comunicazioni tra master e slave viaggiano su protocollo TCP (porta 8182). Ogni slave mantiene una singola connessione TCP con il master.
Verifica del disservizio
Il master host invia periodicamente degli heartbeat sulle reti di management (tutte quelle configurate), per informare gli host slave della sua presenza. Gli host slave utilizzano una sola rete di management per le comunicazioni con l’host master; nel caso in cui la rete utilizzata non fosse più disponibile, proverebbero a comunicare su un’interfaccia di management alternativa (per la configurazione di una rete di management ridondata, far riferimento al paragrafo successivo).
Per capire se un host non è più funzionante, ad esempio per un crash improvviso, o più semplicemente è isolato a livello di rete, vSphere HA utilizza i datastore, che fungono quindi da canale di comunicazione alternativo per la rilevazione degli heartbeat. Quando un host slave non risponde sulle reti di management, vSphere HA effettua una verifica degli heartbeat tramite datastore, per capire se l’host è comunque funzionante, nonostante sia isolato a livello di rete. Il datastore utilizzato per la verifica del disservizio tramite heartbeat è quello con il più alto numero di host ESXi connessi ad esso.
Una volta che il master host considera l’host slave non raggiungibile, lo etichetta come “agent unreachable”. Se l’host non è più funzionante è previsto l'avvio automatico delle VM su altri nodi ESXi. Nel caso in cui l’host fosse isolato a livello di rete, sarebbe necessario l’intervento di un amministratore, oppure si dovrebbe impostare un trigger per il riavvio automatico delle VM su altri host.
Ridondanza per la rete di management
La rete di management è utilizzata da vSphere HA per l’invio delle comunicazioni di heartbeat fra tutti gli host del cluster. VMware raccomanda di adottare una rete ridondata per il management, per non avere punti deboli (single point of failure) nel networking.
Su ogni host del cluster, si dovrebbero avere due interfacce di rete in teaming, come mostrato nell’immagine sotto. Per il bilanciamento del carico fra le due NIC si consiglia di adottare la modalità predefinita “Route based on the originating Port ID”, già descritta nel paragrafo “Bilanciamento del carico di rete e tecniche di failover”, nella sezione del virtual networking.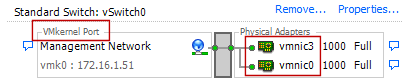
Disponibilità del vCenter server
La strada più veloce per garantire alta disponibilità per il vCenter Server è quella di fornire alta disponibilità ai suoi componenti principali.
- Active Directory
- Database del vCenter Server
Una delle soluzioni più adottate per la continuità del vCenter Server prevede il suo utilizzo su macchina virtuale, affinché possa essere protetto dal servizio vSphere HA.
vSphere HA richiede il vCenter Server solo per la configurazione iniziale. In seguito il servizio funzionerà sugli host in maniera indipendente dal vCenter. Quest’aspetto è importante per capire cosa succede ad un’istanza virtuale di vCenter Server protetta con vSphere HA: se l’host che ospita il vCenter dovesse subire un improvviso blocco operativo (con la conseguenza di avere il vCenter non in linea), vSphere HA sposterebbe il vCenter su un altro host.
Un’altra soluzione prevede l’impiego del vCenter Server Heartbeat (richiede licenza specifica venduta separatamente), che estende la disponibilità di vCenter Server ed esegue, tramite LAN o WAN, il failover del server di gestione e del database su un server in standby. vCenter Server Heartbeat è in grado di rilevare con precisione tutti i componenti del vCenter Server ed è facile da configurare e implementare.
Le istruzioni presenti in questa pagina fanno riferimento alla versione 5.x di VMware vSphere.