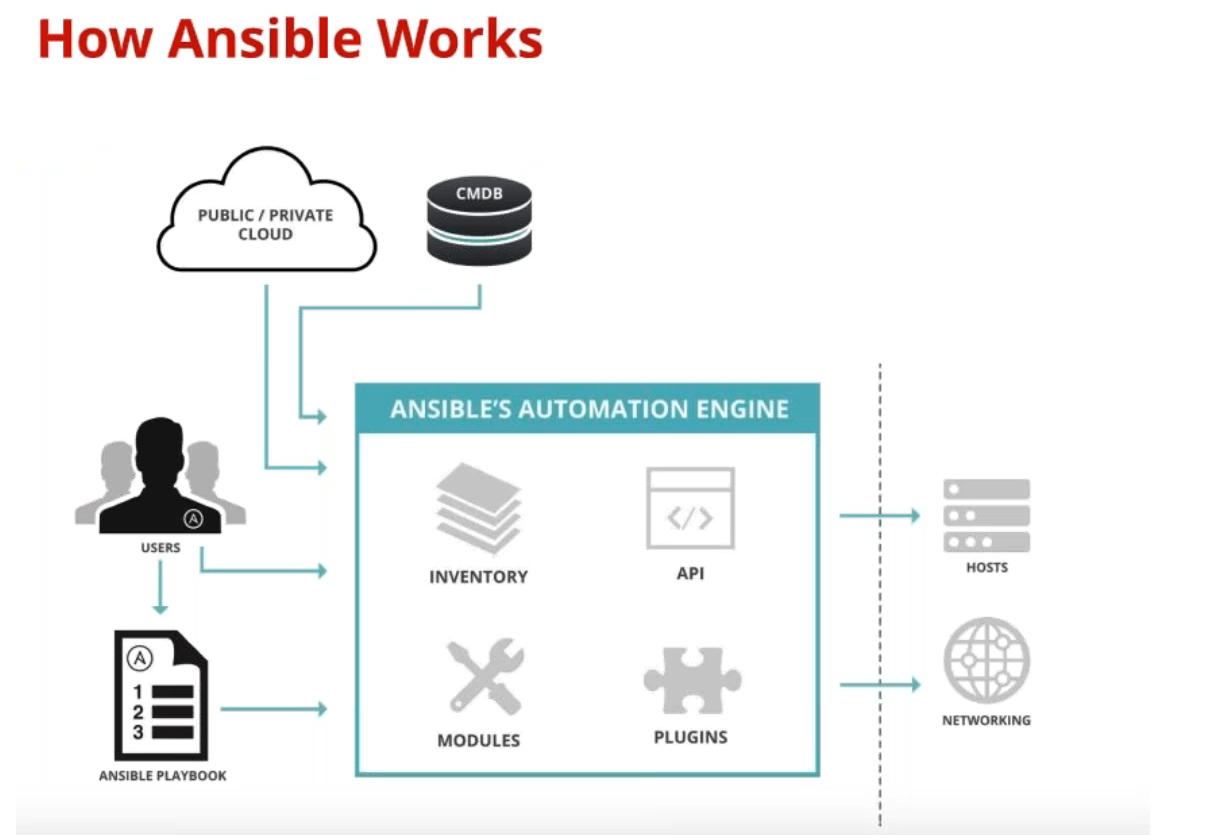
Ansible è un software open source nato per consentire agli amministratori di sistema l’automatizzazione e l’orchestrazione centralizzata delle procedure di configurazione, su sistemi Unix-like. La sua caratteristica principale è il mix di potenza in termini operativi e facilità nell’apprenderne l’utilizzo.
Il software sfrutta due elementi strutturali, che sono i nodi e le macchine controllori. Come si può intuire dal nome, queste ultime sono le macchine che realizzano l’orchestrazione, tramite specifici comandi sui nodi sottostanti, il tutto tramite connessioni SSH e protocollo JSON. La peculiarità di Ansible risiede nel suo essere comprensibile senza particolari competenze di programmazione (quindi non richiede specifiche conoscenze si sintassi e costrutti), unita ad una esecuzione sequenziale dei task di controllo. Gli utilizzi principali riguardano: deploy di applicazioni, gestione distribuita delle configurazioni e orchestrazione dei flussi di lavoro.
Uno dei punti di forza strutturali di Ansible risiede nel suo essere agentless, ossia non richiede agenti software (client, servizi o demoni) sulle macchine target, ma si limita a richiedere un server OpenSSH e WinRM a bordo (in caso di macchine Windows). Questo approccio ha numerosi vantaggi, in primis un risparmio in termini di tempo e risorse sulle macchine da gestire (particolarmente importante in ambienti molto estesi), seguito da una maggiore sicurezza a livello di manutenzione del software presente sugli endpoint nel lungo periodo.
Le specifiche di configurazione in Ansible sono scritte in documenti YAML (formato personalizzato per la serializzazione dei dati) che vengono chiamati Playbook. YAML è un linguaggio molto elementare basato principalmente sull'indentazione e le specifiche di configurazione operano attraverso task – o gestori di eventi – che spiegheremo più avanti. I Playbook, se accuratamente compilati, possono contenere configurazioni anche molto complesse, in grado di gestire situazioni critiche o addirittura inaspettate, sui nodi. Come detto all’inizio, Ansible è open-source, ma ne esistono due implementazioni: Ansible Core gratuito e Ansible Tower. Quest’ultimo appartiene alla software house Red Hat, è a pagamento (con prezzi che variano dai 5000 ai 14000 euro l’anno) e mette a disposizione tutta una serie di funzioni avanzate come la dashboard pe il controllo e la gestione dei nodi, le automazioni (tramite interfaccia RESTfulAPI), API e supporto dedicati.
Scenari di utilizzo e concetti chiave
Ci sono alcuni scenari tipici per l’utilizzo di Ansible, a partire dal Configuration Management, ovvero il setup e la configurazione (iniziale o meno) di server remoti tramite l’installazione di pacchetti, aggiornamenti e servizi specifici. Un altro caso è quello della gestione della Sicurezza, quando si tratta di mantenere macchine aggiornate e risolvere eventuali vulnerabilità in modo rapido e centralizzato, insieme al Provisioning e all’Orchestration delle infrastrutture IT (aggiunta e inizializzazione nuove istanze). Anche la Continuous Delivery può essere gestita tramite i playbook, che permettono appunto il delivery delle applicazioni. Prima di procedere con l’installazione e il primo utilizzo del software, andiamo a definire brevemente i concetti chiave di Ansible:
- INVENTORY: è una collezione di nodi e gruppi ai quali Ansible può connettersi e che può gestire
- TASK: sono le istruzioni che Ansible esegue, in ordine, sui nodi target
- HANDLER: sono istruzioni che vanno eseguite come conseguenza di una determinata azione
- PLAY E PLAYBOOK: i Play sono una serie di task ordinati da eseguire sui nodi selezionati dall’inventario. Un playbook è un file che contiene uno o più play
- ROLE: rappresentano una serie di contenuti strettamente correlati che permetto di gestire meglio e mantenere una serie di playbook
Nello specifico, l’inventario di Ansible è una collezione di nodi (host) con determinate caratteristiche e gruppi di nodi che possono essere connessi e gestiti tutti insieme, singolarmente o in gruppi.
Installazione e funzionamento
Installare Ansible è piuttosto semplice, seppur dipendente dal sistema operativo in uso e computer sul quale viene installato e dal quale si opera prende il nome di Ansible Management Node, ovvero quello su cui l’utente crea i playbook. La figura seguente mostra una lista di comandi da impartire per l’installazione da CLI (interfaccia a riga di comando).

Playbook
I playbook e i moduli verranno eseguiti sui nodi riepilogati nell’Inventory (l’inventario che raccoglie gli estremi di tutti i nodi su cui opereremo), che sono quelli disponibili per l’esecuzione del deployment: i nodi destinatari vengono chiamati nodi target. I moduli, a loro volta, sono porzioni di codice trasferite ai nodi per essere eseguiti e soddisfare la dichiarazione di un determinato task. Possono essere usati da CLI o automatizzati in task all’interno di un playbook. Sul sito www.ansible.com è disponibile la documentazione completa di tutti i moduli previsti, suddivisi per categoria: moduli per Windows, per la rete, per il web, di sistema, di comando e di utilità etc.
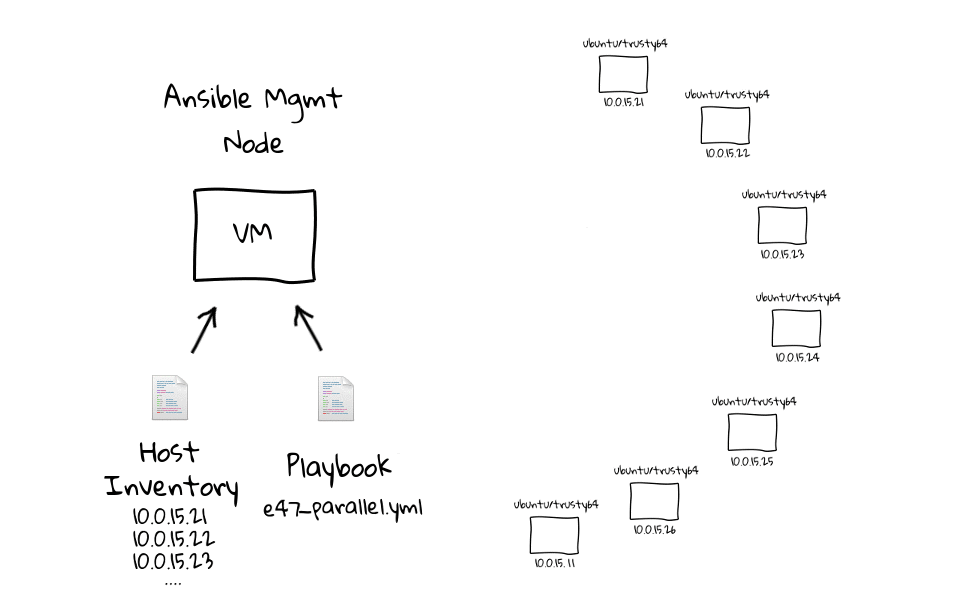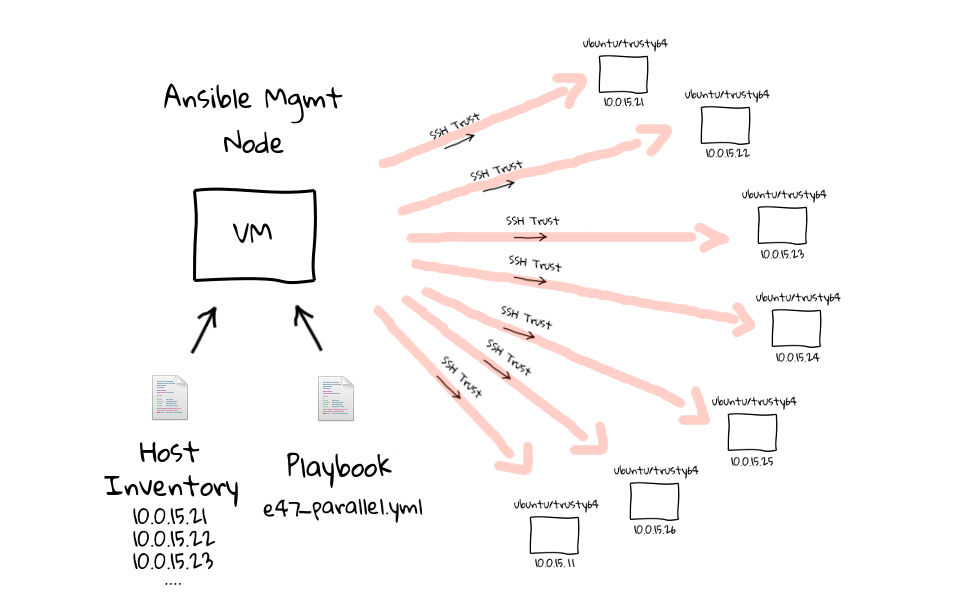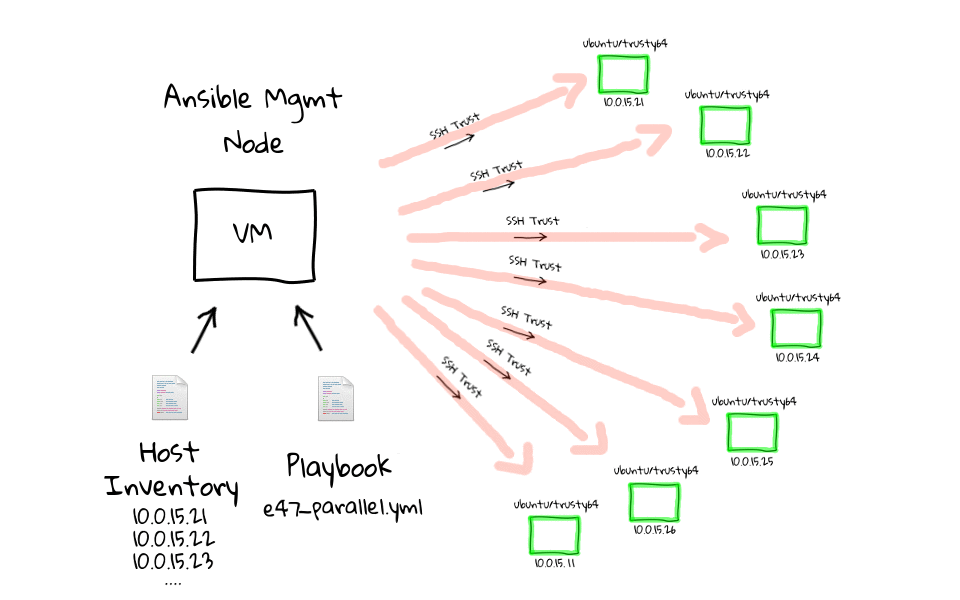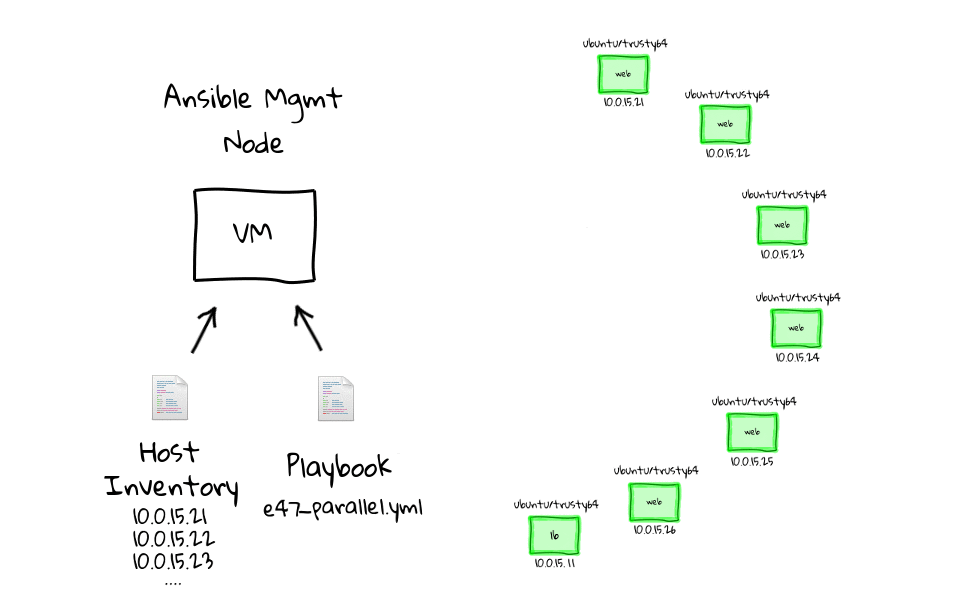
La documentazione è fondamentale perché descrive, per ciascun modulo, i parametri e la configurazione necessaria per assicurarne il corretto funzionamento. Non tutte le combinazioni possibili sono coperte dai moduli standard del software, ma è un limite a cui si può facilmente porre rimedio costruendone di specifici. A questo scopo si utilizzano moduli di categoria Command, ovvero che eseguono un comando e sono di quattro tipi diversi: Command, Shell, Script e Raw.
Command
Nel primo caso, il Command riceve un comando e lo esegue sull’host target, Shell a sua volta esegue un comando da una shell come /bin o /sh, in modo da poter utilizzare anche intere pipe. Script esegue uno script locale sul nodo remoto, prima di trasferirlo su quest’ultimo ed infine, Raw esegue un comando senza passare dai moduli di Ansible: in pratica lavora in modo esterno al software.
In Ansible troviamo gli ad-hoc commands, che sono comandi eseguibili liberamente senza che sia necessario salvarli e ripeterli in un secondo momento. I comandi ad hoc possono essere digitati al bisogno e senza vincoli, quindi senza collocare le rispettive operazioni in un playbook. Vediamo un paio di esempi di seguito:
$ ansible all –m ping
questo comando ordina l’esecuzione del comando ping su tutti i nodi presenti nell’Inventory, a cui i nodi risponderanno (almeno quelli “alive” cioè attivi).
$ ansible all –m command -a “uptime”
è un comando che esegue sui nodi del gruppo il modulo Command con attributo uptime, allo scopo di ottenere l’uptime di tutti i server del gruppo stesso.
Facts
Passiamo ora ai Facts: anche noti come Discovered Facts. Sono porzioni di informazioni fornite dai nodi e che possono essere memorizzate come variabili per un successivo utilizzo nei playbook. Sono utili in molti casi, ad esempio quando vogliamo conoscere gli attributi dei sistemi sui quali stiamo lavorando ed un esempio è visibile di seguito:
$ ansible localhost -m setup
localhost | success >> {
"ansible_facts": {
"ansible_default_ipv4" : {
"address": "192.168.1.37",
"alias": "wlan0",
"gateway": "192.168.1.1",
"interface": "wlan0",
"macaddress": "c4:85:08:3b:a9:16",
"mtu": "1500",
"netmask": "255.255.255.0",
"network": "192.168.1.0",
"type": "ether"
},
},
}
Per effettuare questa operazione si utilizza un apposito modulo setup (-m setup) che esegue un retrieve (ricerca e recupero) delle informazioni tecniche dell’host target e le riepiloga in modo che possano essere utilizzate, ad esempio, in un playbook. I Facts non sono l’unico tipo di variabile utilizzabile, queste sono genericamente chiamate Variables, che possono avere come sorgente parametri di comandi impartiti via CLI, Play e Task, file esterni, Facts, Roles e l’intero Inventory.
Altro concetto importante di Ansible sono i Task, ossia le istruzioni che Ansible esegue in sequenza sui nodi target. In breve un task è l’applicazione di un modulo di Ansible finalizzata a eseguire una certa operazione.
Ogni playbook contiene una lista di task che vengono eseguiti su tutte le macchine target. Tra i moduli più usati abbiamo:
- file: permette di creare una directory se non esiste;
- yum: permette di installare un pacchetto non presente nel sistema;
- service: esegue il servizio passato come parametro;
- template: costruisce un file di configurazione a partire da un template specificato;
- get_url: recupera un file archivio dall’URL specificato come parametro;
- git: clona un repository da codice sorgente.
Un esempio di task all'interno di un playbook potrebbe essere il seguente:
task:
-name: httpd package is present
yum:
name: httpd
state: latest
-name: latest index.html is present
copy:
src: files/index.html
dest: /var/www/html/
-name: restart httpd
service:
name: httpd
state: restarted
Nel dettaglio, il primo task installa un pacchetto chiamato httpd - Apache - che è già presente nel sistema e per controllare se sia necessario sovrascriverlo sfrutta il controllo di stato latest (a indicare di installare l’ultima versione, se il package è lo stesso l’operazione non sarà eseguita). Ogni task ha un nome: pur non essendo necessario è utile per evitare di fare confusione e per identificarlo velocemente.
Nel secondo task carichiamo un file (quello il cui nome e percorso seguono src:) dalla macchina locale e con il modulo copy lo scriviamo nei server il cui percorso che segue è definito dalla direttiva dest: .L’ultimo task riavvia Apache per applicare le modifiche apportate.
Handler tasks
Passiamo adesso agli Handler, ovvero istruzioni che vanno eseguite come conseguenza di una determinata azione. Gli handler sono speciali task eseguiti alla fine di un play oppure, se notificato da un altro task, al verificarsi di un cambiamento: ad esempio, se un task esegue l’aggiornamento di un database o di un file di configurazione, provvede anche a notificare l’accaduto all’apposito handler perché riavvii il servizio relativo, al fine di applicare la modifica.
task:
-name: httpd package is present
yum:
name: httpd
state: latest
notify: restart httpd
-name: latest index.html is present
copy:
src: files/index.html
dest: /var/www/html/
handlers:
-name: restart httpd
service:
name: httpd
state: restarted
in essa riprendiamo l’esempio del task aggiungendo l’istruzione notify:restart httpd che rimanda all’handler restart httpd. Si noti che l’handler viene chiamato solo se si verifica effettivamente la condizione di notify.
Nella seconda parte di questo articolo approfondiremo altri aspetti e terminologie della piattaforma, come i Template, la formattazione condizionale dei playbook e alcuni esempi pratici.

")